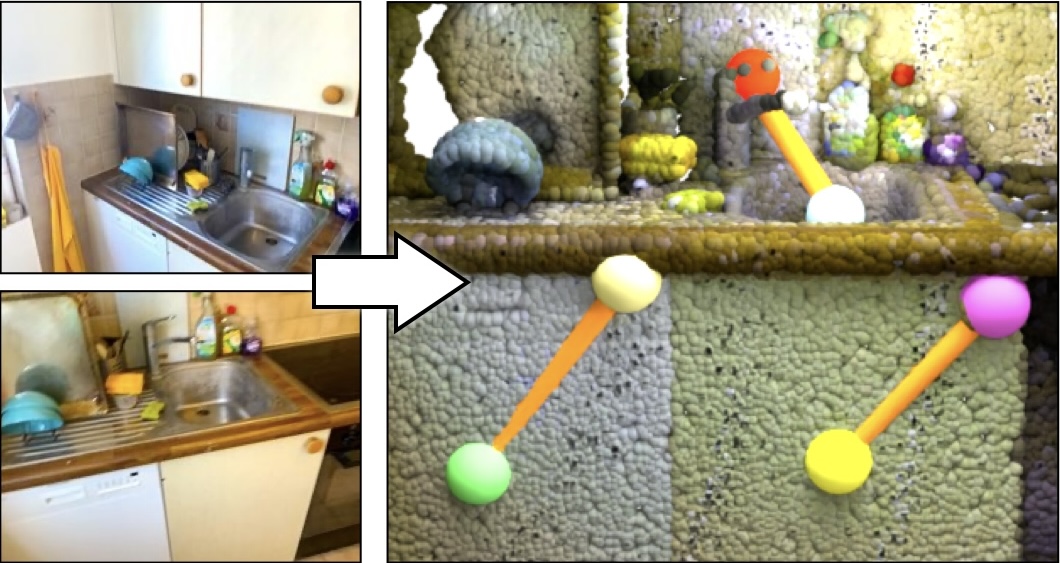
We introduce the task of predicting functional 3D scene graphs for real-world indoor environments from posed RGB-D images. Unlike traditional 3D scene graphs that focus on spatial relationships of objects, functional 3D scene graphs capture objects, interactive elements, and their functional relationships. Due to the lack of training data, we leverage foundation models, including visual language models (VLMs) and large language models (LLMs), to encode functional knowledge. We evaluate our approach on an extended SceneFun3D dataset and a newly collected dataset, FunGraph3D, both annotated with functional 3D scene graphs. Our method significantly outperforms adapted baselines, including Open3DSG and ConceptGraph, demonstrating its effectiveness in modeling complex scene functionalities. We also demonstrate downstream applications such as 3D question answering and robotic manipulation using functional 3D scene graphs.

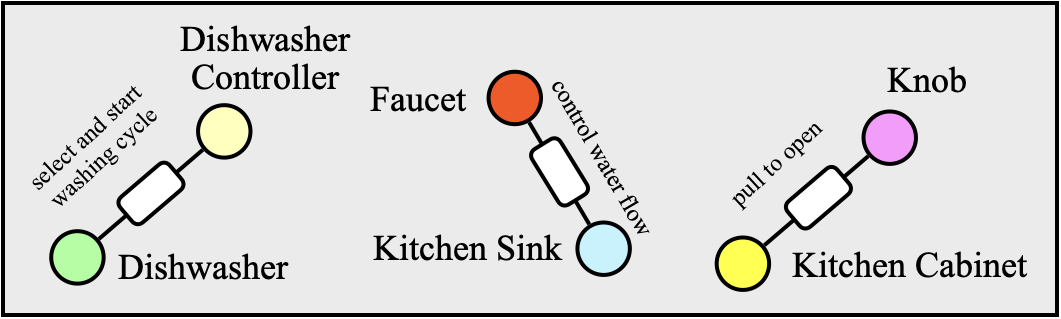
Scene interactive elements and their functional relationships between objects are exploited by our approach.

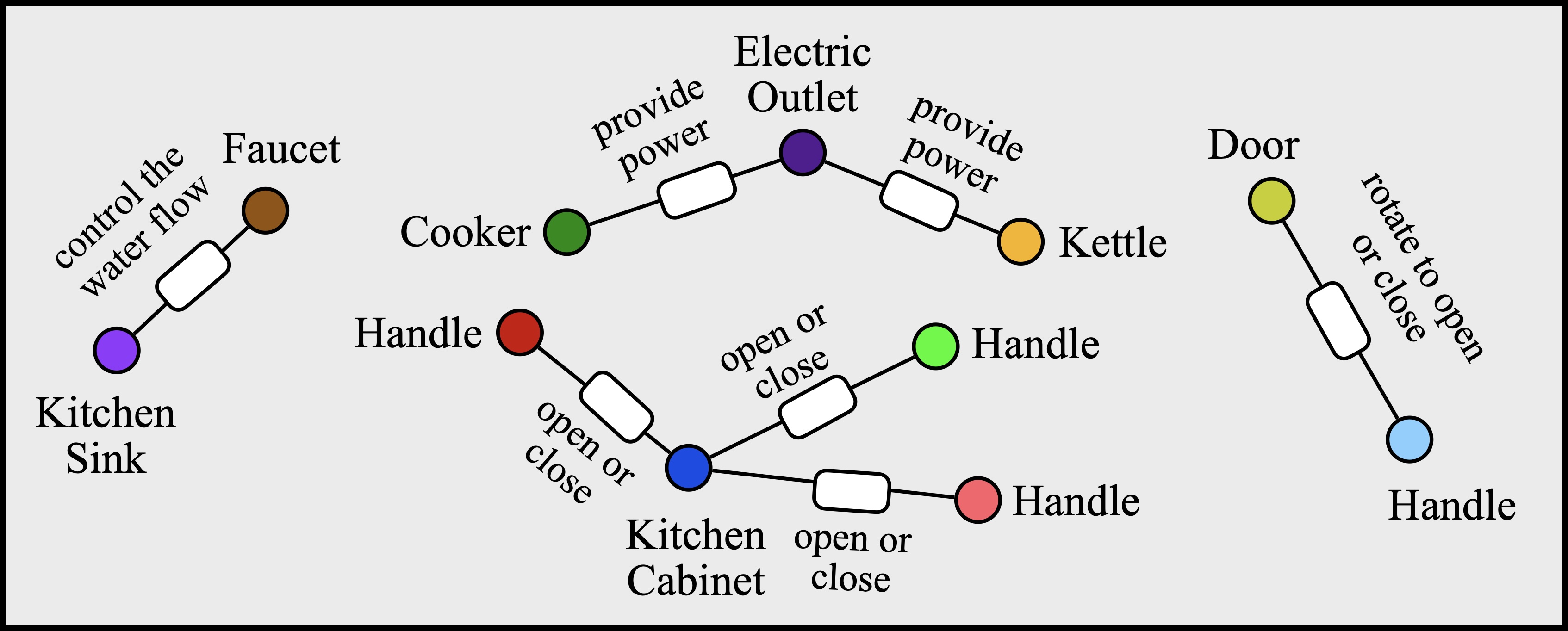


FunGraph3D dataset is constructed with multi-sensor data (i.e., high-fidelity 3D reconstructions, consumer-device video captures, egocentric human-scene interaction videos) and functional 3D scene graph annotations.
@inproceedings{zhang2025open,
title = {{Open-Vocabulary Functional 3D Scene Graphs for Real-World Indoor Spaces}},
author = {Zhang, Chenyangguang and Delitzas, Alexandros and Wang, Fangjinhua and Zhang, Ruida and Ji, Xiangyang and Pollefeys, Marc and Engelmann, Francis},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}